| Reward Term | Weight | Reward Term | Weight |
|---|---|---|---|
| Ball velocity tracking | 3.0 | Ball-target reached | 50.0 |
| Ball speed tracking | 2.0 | Robot-obstacle collision | -10.0 |
| Ball heading tracking | 2.0 | Ball-obstacle collision | -10.0 |
| Robot-ball distance | 0.05 | Foot slip | -0.1 |
| Robot-ball yaw | 2.0 | Upright | 1.0 |
| Ball-target progress | 2.0 | Body angular velocity | -0.05 |
| Swing phase | 3.0 | Angular momentum | -0.5 |
| Stance phase | 2.0 | DoF position limits | -1.0 |
| Pose arms | 1.0 | Action rate (L2) | -0.1 |
| Pose legs | 1.0 | Foot swing height | -0.25 |
| Feet distance | -6.0 | Soft landing | -1e-5 |
| Foot-foot contact | -5.0 | Self-collisions | -1.0 |
| Nonfoot-ball contact | -2.0 |
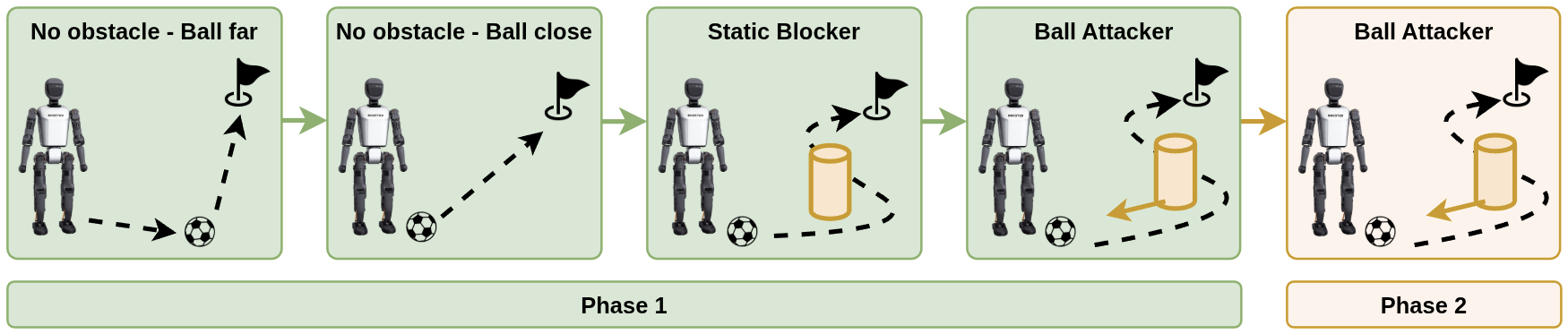
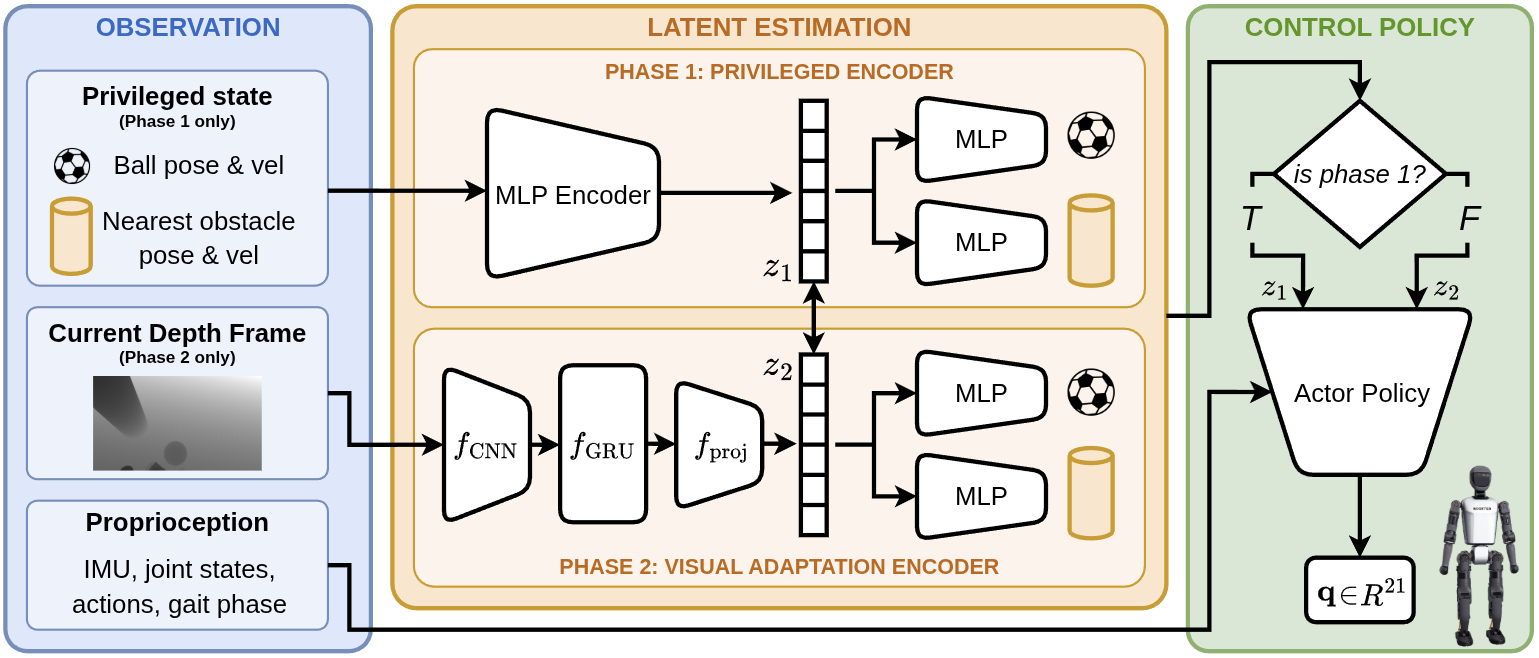
Table. Reward terms and weights for training the dribbling policy.