Context Matters! Relaxing Goals with LLMs for Feasible 3D Scene Planning
🎉 Paper accepted to ICRA 2026 🎉
🎥 Summary Video
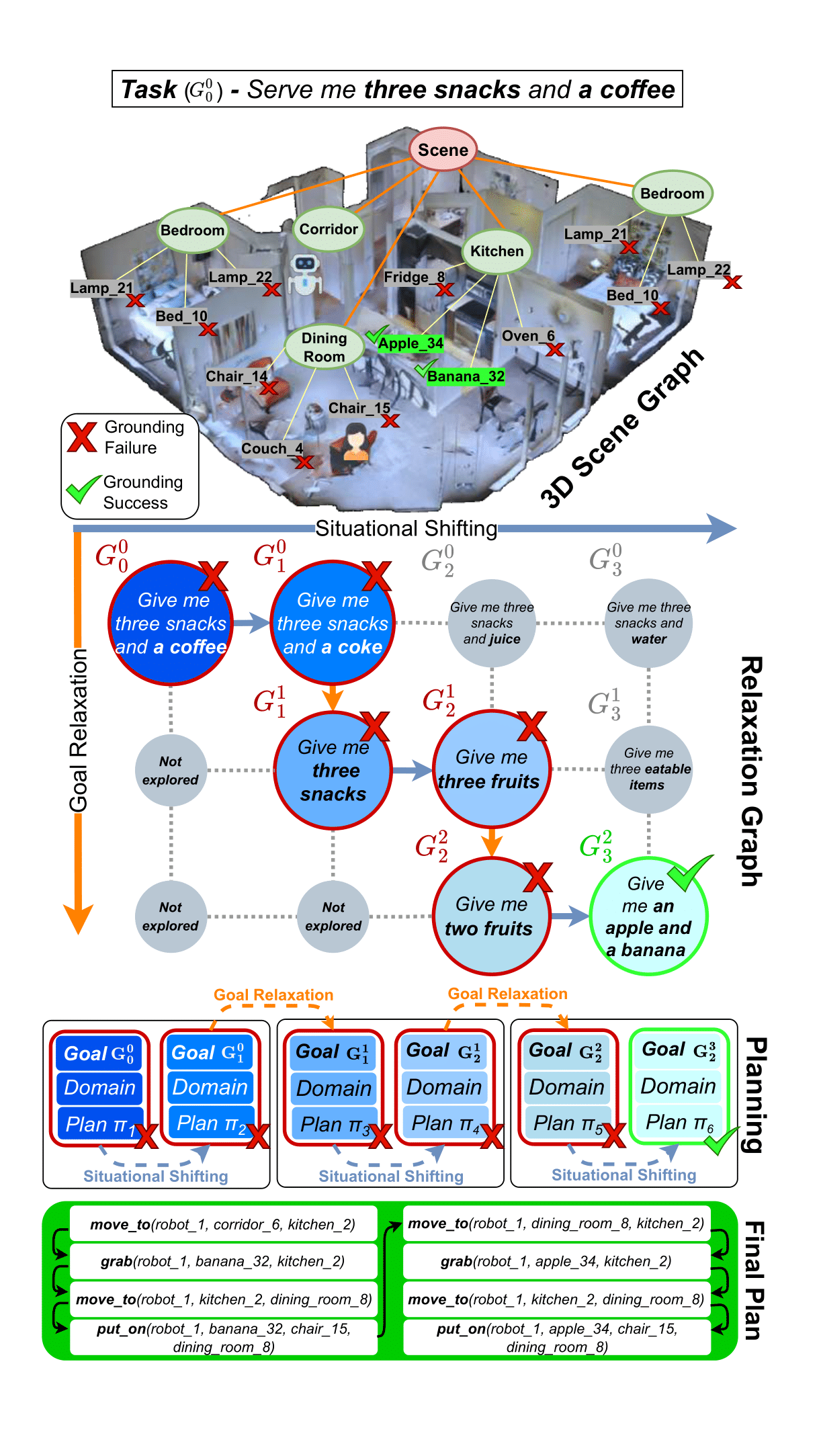
🌟 Motivations
📝 Contributions
🌟 Motivations
📝 Contributions
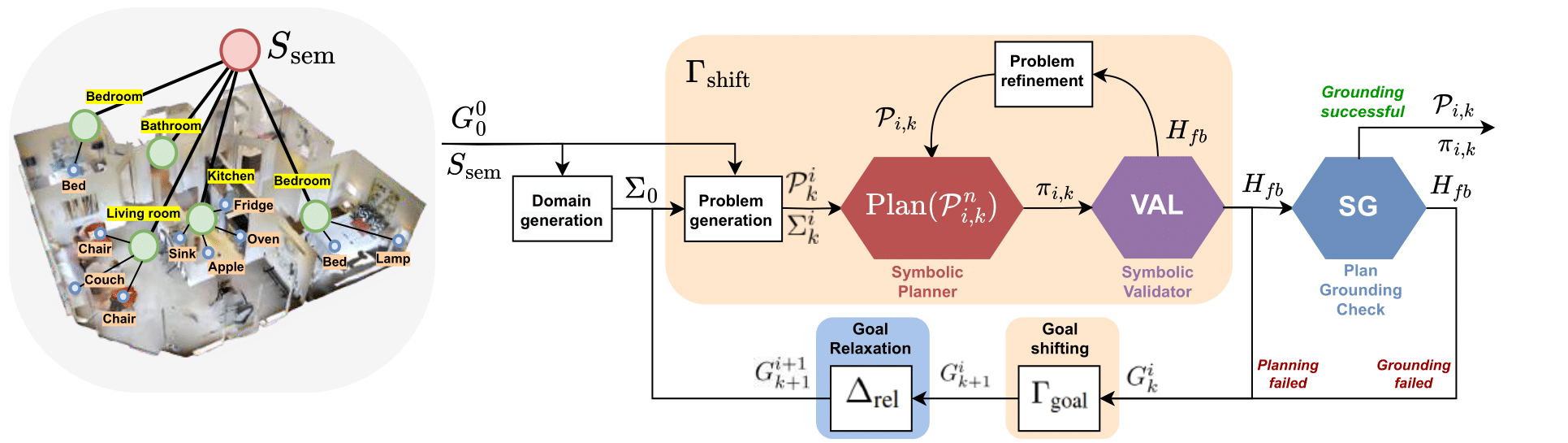
We release a benchmark of 141 planning tasks built on top of the 3D Scene Graph (3DSG) dataset. Each task pairs a natural-language goal with an augmented scene graph and a PDDL domain, and is designed to stress-test goal relaxation when strict goals are infeasible in the given environment. The benchmark spans 6 thematic splits and 10 house-scale 3DSG scenes; 51 of the 141 instances are marked as relaxation-prone in the task specifications.
| Split | Problems | Scene instances | Relaxation-prone | PDDL domain |
|---|---|---|---|---|
general |
11 | 66 | 24 | general-domain.pddl |
office_setup |
8 | 24 | 9 | office-setup-domain.pddl |
dining_setup |
6 | 18 | 3 | dining-setup-domain.pddl |
house_cleaning |
6 | 18 | 12 | house-cleaning-domain.pddl |
laundry |
6 | 6 | 3 | laundry-domain.pddl |
pc_assembly |
3 | 9 | 0 | pc-assembly-domain.pddl |
| Total | 40 | 141 | 51 | — |
A problem is a task template; each template is instantiated on every 3DSG scene listed in its
graph field, yielding one scene instance per (problem, scene) pair.
The dataset folder in the project repository contains:
general.json,
dining_setup.json, …) listing problems with fields:
description, goal, graph (3DSG scene names),
objects (objects to inject into the scene), and
relaxation_expected (whether relaxation is needed for feasibility).house-cleaning-domain.pddl)
defining actions and predicates for that task family.dataset_creation.py and dataset_utils.py
to build augmented 3DSGs from the JSON specs; optional LLM-generated object descriptions via
--description..npz files under
dataset/3dscenegraph/ (not shipped in the repo; see below).
After generation, each instance is stored under
<split>/<scene_name>/<problem_id>/ with:
task.txt (goal), description.txt, init_loc.txt (random robot start room),
and the augmented scene graph as <scene_name>.npz / .json.
Scenes are taken from the 3DSG tiny split
(Allensville, Parole, Shelbiana, Kemblesville)
and medium split
(Klickitat, Lakeville, Leonardo, Lindenwood,
Markleeville, Marstons).
1. Generate the augmented scenes
.npz files in dataset/3dscenegraph/:
Allensville, Kemblesville, Klickitat, Lakeville,
Leonardo, Lindenwood, Markleeville, Marstons,
Parole, Shelbiana.export OPENAI_API_KEY=<your OpenAI API key>
python3 dataset/dataset_creation.py
Optionally add LLM-written object descriptions with
python3 dataset/dataset_creation.py --description.
2. Run planning experiments
Pipelines read tasks from dataset/ (configured via data_path in
config/config.yaml). Run a baseline with Hydra, for example:
export OPENAI_API_KEY=<your OpenAI API key>
python3 main.py pipeline=cm
Available pipelines: cm, delta, sayplan, llm_planner.
All six splits are evaluated by default. Override parameters on the command line, e.g.
python3 main.py pipeline=cm pipeline.workflow_iterations=3.
@article{musumeci2025context,
title={Context Matters! Relaxing Goals with LLMs for Feasible 3D Scene Planning},
author={Musumeci, Emanuele and Brienza, Michele and Argenziano, Francesco and Suriani, Vincenzo and Nardi, Daniele and Bloisi, Domenico D},
journal={arXiv preprint arXiv:2506.15828},
year={2025}
}